Alert - You are welcome to use any template, but please do not use my posts.
Naive Bayes Model
A self use function for Naive Bayes classifier
ML
Classification
Author
Creo Hsia
Published
October 14, 2024
We build a Naive Bayes classifier that can handle any classification problem, assuming continuous variables follow a normal distribution. This classifier is not limited to the specific problem in the exercises.
1 Function Bayesclasifier
The following function fits a Naive Bayes model to the data, estimating prior probabilities and conditional probabilities for both continuous and categorical features. This function takes four inputs: the data, the response (a character string specifying which column contains the class labels), the prior (if provided), and the Laplace smoothing parameter. The output is a list containing the conditional probabilities for each variable, the prior probabilities, an indicator of which columns are numeric or categorical, and the levels of the class labels. The returned list is of class naiveBayes, which allows for method dispatching specific to this model.
Code
Bayesclasifier <-function(data, response, prior =NULL, alpha =0) {# Step 1: Extract the target variable (response)# 'label' contains the target class from the 'response' column of the data label <- data[[response]] label_counts <-table(label) level <-unique(label)# Identify unique classes in the target variable# Remove the response column from the data #(since it should not be used as a predictor) data[[response]] <-NULL# Step 2: Calculate prior probabilities if not providedif (is.null(prior)) { prior <-prop.table(label_counts) }# Step 3: Identify numeric and categorical columns is_num <-sapply(data, function(x) is.numeric(x))# Step 4: Process numeric and categorical columns separately tbl <-lapply(data,function(col){if (is.numeric(col)){# For numeric columns, calculate the mean and variance#for each class in the target variable means <-tapply(col, label, mean,na.rm =TRUE) sd <-tapply(col, label, sd,na.rm =TRUE)cbind(means,sd) }else {# For categorical columns, calculate smoothed counts # and conditional probabilities# Do not display the count of NA values (this is the default behavior) counts <-table(label, col)# Apply Laplace smoothing to avoid zero probabilities smoothed_probs <-sweep(counts + alpha, 1, label_counts+alpha*ncol(counts), "/")# Calculate conditional probabilitiesreturn(smoothed_probs) } })# Return the model as a list containing: #1) prior probabilities, 2) tables of statistics, 3) and metadata result <-list(prior = prior, tables = tbl, isnumeric=is_num,level=level)# Assign a class to the result for method dispatchclass(result) <-"naiveBayes_clasifier"return(result)}
2 Function predict.naiveBayes_clasifier
The predict function takes a trained Naive Bayes model and new data as inputs, and returns predicted class labels or class probabilities depending on the specified type. For missing values (NA), the function handles them by assigning neutral probabilities (effectively ignoring them in the likelihood calculation).
Code
predict.naiveBayes_clasifier <-function(model, newdata, type ="class") { logprior <-log(model$prior) len <-length(model$prior)# Match newdata columns with model attributes match_idx <-match(names(model$tables), names(newdata)) # Step 3: Preallocate log probability matrix for faster computation Logprob <-matrix(0, nrow = len, ncol =nrow(newdata),dimnames =list(model$level,NULL))# Step 1: Convert categorical variables to factors with matching levelsfor (v inseq_along(match_idx)) {if (model$isnumeric[v]){ nd <- newdata[, match_idx[v]] tbl <- model$tables[[v]] means <- tbl[, 1] sd <- tbl[, 2] notna <-!is.na(nd) Logprob[,notna] <-Logprob[,notna]+vapply(nd[notna],function(x) dnorm(x,means,sd,log=TRUE),numeric(len)) }else { nd <-factor(newdata[,match_idx[v]],levels =colnames(model$tables[[v]])) notna <-!is.na(nd) Logprob[,notna] <-Logprob[,notna]+log(model$tables[[v]][,nd[notna]]) } }# Step 5: Add log-priors to the computed log-likelihoods Logprob <-sweep(Logprob, 1, logprior, "+")# Step 6: Return predictions based on the specified type ('class' or 'raw')if (type =="class") { pred_classes <- model$level[apply(Logprob,2,which.max)]return(pred_classes) } else {# If type == "raw", return probabilities for all classes probs <-exp(Logprob) # Convert log-probabilities back to normal scale# Normalize probabilities so they sum to 1 probs <-apply(probs,2,function(x)x/sum(x) ) return(t(probs)) }}
3 Function confusion_matrix and roc_auc
The first function computes the confusion matrix, which compares the true class labels with the predicted class labels to evaluate the performance of the classification model.
Input:
true_labels: A vector of true class labels for the dataset.
predicted_class: A vector of predicted class labels for the dataset. This is typically the output after selecting the class with the highest predicted probability for each instance.
Output:
A confusion matrix, where rows represent the actual class labels and columns represent the predicted class labels.
The second function computes the ROC curve and Area Under the Curve (AUC) for each class in the classification problem.
Input: the same as above
Output:
A list containing:
roc_data: A data frame with columns FPR (False Positive Rate), TPR (True Positive Rate), and class for each class, representing the ROC curve points for each class.
auc: A named vector where each entry is the AUC value for one class, with the class names as the vector names.
While these functions can handle binary classification, they are especially suited for multi-class classification problems. In multi-class classification, the “one-vs-all” (or “one-vs-rest”) approach is applied. This means that for each class, the function treats it as the positive class and considers all other classes as the negative class.
Code
# Function to create a confusion matrix based on true labels and predicted class labelsconfusion_matrix <-function(true_labels, predicted_class) { class_names <-unique(c(true_labels, predicted_class))# Create an empty confusion matrix conf_matrix <-matrix(0, nrow =length(class_names), ncol =length(class_names),dimnames =list("Actual"= class_names, "Predicted"= class_names))# Populate the confusion matrixfor (i inseq_along(true_labels)) { true_class <- true_labels[i] pred_class <- predicted_class[i] conf_matrix[true_class, pred_class] <- conf_matrix[true_class, pred_class] +1 }return(conf_matrix)}roc_auc <-function(true_labels, predicted_probs) {# Get unique class names classes <-colnames(predicted_probs)# Internal function to compute sensitivity and specificity with vectorized operations compute_roc_auc <-function(binary_labels, pos_prob) {# Sort the predicted probabilities and corresponding labels once order_index <-order(pos_prob, decreasing =TRUE) sorted_labels <- binary_labels[order_index]# Number of positive and negative samples M <-sum(sorted_labels ==1) N <-sum(sorted_labels ==0)# Cumulative sum to calculate sensitivity (sen) and specificity (spe) sen <-cumsum(sorted_labels ==1) # True positives as we go down the list spe <-cumsum(sorted_labels ==0) # False positives as we go down the list# Sensitivity and specificity as ratios TPR <-c(0, sen / M) FPR <-c(0, spe / N)# Calculate AUC using the trapezoidal rule (efficiently using vectorized operations) auc <-sum((FPR[-1] - FPR[-length(FPR)]) * (TPR[-1] + TPR[-length(TPR)])) /2# Return results as a matrix for better performancereturn(list(roc =data.frame(FPR = FPR, TPR = TPR), auc = auc)) }# Check if it's a binary classification problemif (length(classes) ==2) { class_name <- classes[1] binary_labels <-ifelse(true_labels == class_name, 1, 0) pos_prob <- predicted_probs[, class_name]# Compute ROC for the binary classification roc_auc_result <-compute_roc_auc(binary_labels, pos_prob) roc_data <- roc_auc_result$roc roc_data$class <- class_name # Add class column auc <-setNames(roc_auc_result$auc, class_name) # Return AUC as named vector } else {# For multi-class classification, use one-vs-all approach roc_data_list <-list() auc <-setNames(rep(NA, length(classes)), classes) # Initialize a named vector for AUC# Loop through each class and calculate sensitivity and specificityfor (class_name in classes) { binary_labels <-ifelse(true_labels == class_name, 1, 0) pos_prob <- predicted_probs[, class_name]# Compute ROC for the current class class_roc_auc_result <-compute_roc_auc(binary_labels, pos_prob) class_roc_data <- class_roc_auc_result$roc class_roc_data$class <- class_name # Add class column# Store ROC data and AUC for the current class roc_data_list[[class_name]] <- class_roc_data auc[class_name] <- class_roc_auc_result$auc # Assign AUC to the named vector }# Combine ROC results for all classes into a single data frame roc_data <-do.call(rbind, roc_data_list) } result <-list(roc_data = roc_data, auc = auc)class(result) <-"roc_auc"return(result)}
4 Function plot.roc_auc
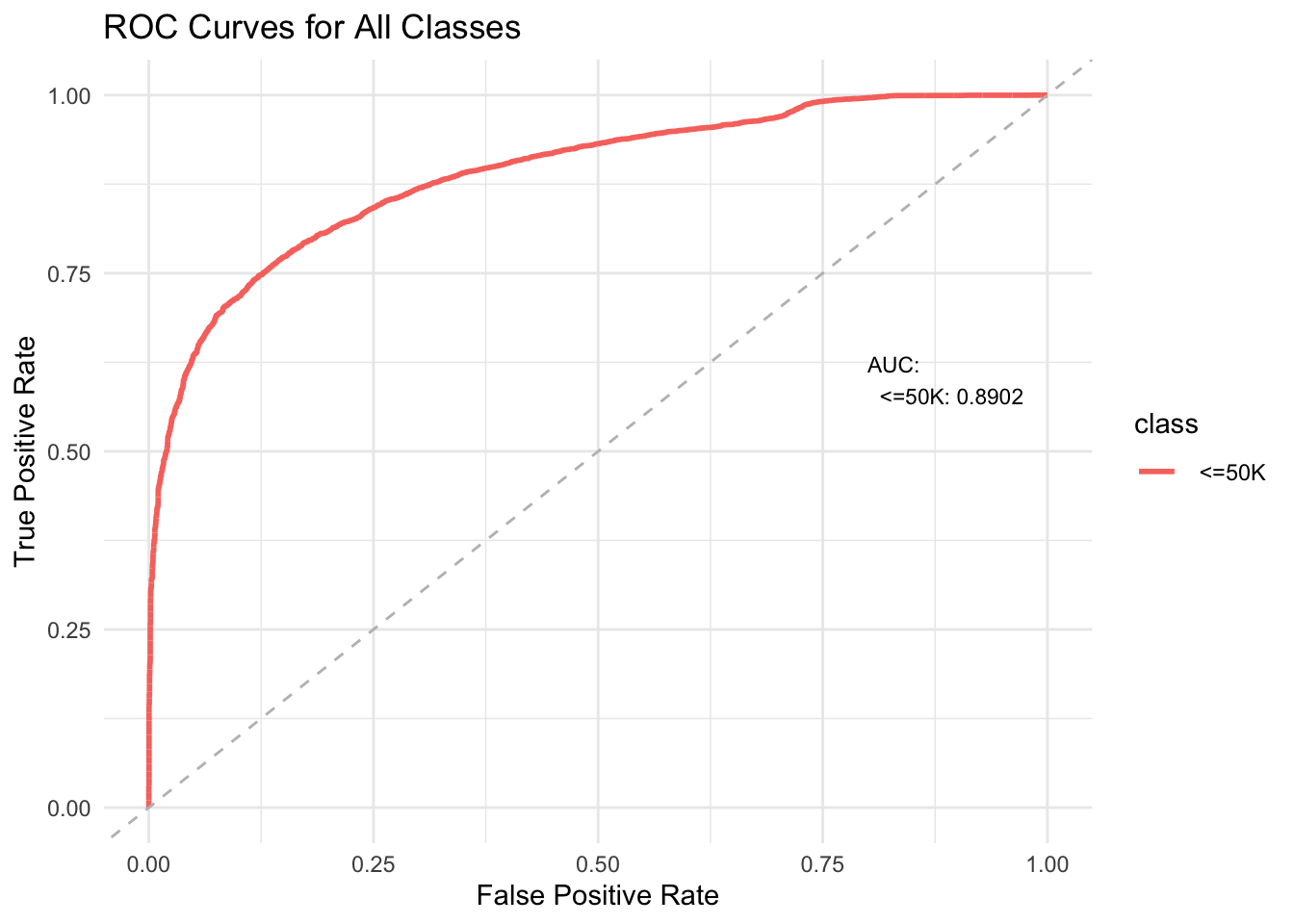
A ggplot2 plot displaying the ROC curves for all classes. Each class is represented by a different color, and the AUC values are shown on the plot to summarize the classifier’s performance for each class.
Code
plot.roc_auc <-function(x, ...) {# Extract ROC data and AUC values roc_data <- x$roc_data auc_values <- x$auc# Create a data frame for AUC values to annotate auc_annotations <-data.frame(class =names(auc_values),auc =round(auc_values, 4),label =paste(names(auc_values), ": ", round(auc_values, 4), sep ="") )# Plot all ROC curves, using different colors for each class p <-ggplot(roc_data, aes(x = FPR, y = TPR, color = class)) +geom_line(linewidth =1) +geom_abline(slope =1, intercept =0, linetype ="dashed", color ="gray") +labs(title ="ROC Curves for All Classes",x ="False Positive Rate", y ="True Positive Rate") +theme_minimal()# Annotate AUC values at the top-right corner without any box or frame auc_text <-paste("AUC:\n", paste(auc_annotations$label, collapse ="\n")) p <- p +annotate("text", x =0.8, y =0.6, hjust =0,label = auc_text, size =3, color ="black")# Display the plotreturn(p)}
5 A real example
We apply the custom Naive Bayes classifier to the Adult dataset for classification (the data can be found in Github) . We also compare its performance in terms of speed with the naiveBayes function from the e1071 R package.
library(ggplot2)data <-read.csv("adult.data",na.strings =" ?", header=FALSE)newdata <-read.table("adult.test",sep=",", skip =1,na.strings =" ?")newdata$V15 <-gsub("\\.$", "", newdata$V15)system.time({ model <-Bayesclasifier(data,"V15",alpha =1) pred <-predict(model,newdata,"raw") roc <-roc_auc(newdata$V15,pred)})#>| user system elapsed #>| 0.159 0.006 0.165library(e1071)system.time({ model2 <- e1071::naiveBayes(V15~.,data=data) pred2 <-predict(model2,newdata)})#>| user system elapsed #>| 1.299 0.006 1.305
This function prints a summary of the fitted model, including the prior probabilities, the conditional probabilities for each variable, and an indication of whether each variable is numeric or categorical.
Code
print.naiveBayes_clasifier <-function(model) {cat("Naive Bayes Model\n")cat("=================\n")# Print class levelscat("\nClass Levels:\n")print(model$level)# Print prior probabilitiescat("\nPrior Probabilities:\n")print(model$prior)# Loop through the model tables to display statistics for each featurecat("\nFeature Statistics:\n")for (i inseq_along(model$tables)) { feature_name <-names(model$tables)[i]cat("\nFeature:", feature_name, "\n")if (model$isnumeric[i]) {# For numeric features, print mean and standard deviationcat("Type: Numeric\n") stats <- model$tables[[i]]print(data.frame(Mean = stats[, 1], SD = stats[, 2])) } else {# For categorical features, print conditional probabilitiescat("Type: Categorical\n") probs <- model$tables[[i]]print(as.data.frame.matrix(probs)) } }cat("\n=================\n")}